What is so natural about the seemingly unnatural "natural parameters"?
Table of Contents
Standard parameterization
The standard parameterization of the Gaussian distribution is given by the following:
$$ p_\theta(x) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp \left\{ -\frac{(x-\mu)^2}{2\sigma^2} \right\} $$where $\mu$ is the mean and $\sigma^2$ is the variance. Hence, the set of all Gaussian distributions exist on a two-dimensional manifold, where the coordinates are given by the following:
$$\theta_1 = \mu\\ \theta_2 = \sigma$$This article will detail alternate parameterization for the Gaussian distribution, and more broadly for the exponential-family distributions, to which the Gaussian distribution belongs. Specifically, we will look at the natural and expectation parameterization, and examine their interrelation. Additionally, it will detail how to leverage the intrinsic structure of these parameterization spaces to attain computationally efficient gradients. These gradients, known as the natural gradients, are not only computationally efficient in conjugate exponential-family distributions, but also converge to the solution in fewer iterations.
Moment/Expectation parameterization
The expectation parameterization of the exponential-family distributions is built using the potential functions, also known as the sufficient statistics:
$$\phi_\alpha: X \to \mathbb{R}; \alpha \in \mathbb{I}$$Here $\alpha$ belongs to the index set, i.e., 1, 2, 3,… and the functions are given by $X^\alpha$:
$$ \phi_1(x) = x \\ \phi_2(x) = x^2 \\ \vdots $$The expectation of the potential functions gives us the moments of a distribution $p$. The following are the moments of a Gaussian distribution:
$$ \begin{aligned} \eta_1 =& \mathbb{E}_p[\phi_1(x)] = \mu \\ \eta_2 =& \mathbb{E}_p[\phi_2(x)] = \mu^2 + \sigma^2 \\ \vdots \end{aligned} $$As we can see, the expectation parameters $\eta$ are related to the standard parameters $\theta$. The space of the expectation parameters is given by:
$$ \mathcal{M} := \{\eta \in \mathbb{R}^d | \exists p \ \text{s.t.} \ \mathbb{E}_p[\phi_\alpha(x)]=\eta_\alpha \ \forall \alpha \in \mathbb{I}\} $$i.e., for any given $\eta$, there exists a distribution $p$ whose moments match the values of the parameter $\eta$.
Canonical/Exponential/Natural parameterization
The canonical form of the Gaussian distribution (which belongs to the exponential-family of distributions), is given by the following:
$$ p_\lambda(x) = \exp \left\{ \langle \lambda, \phi(x) \rangle - A(\lambda) \right\} $$Here, $\langle\cdot,\cdot\rangle$ is the dot product, $\phi(x)$ are the moments $\phi_\alpha(x)$, and $\lambda$ are the natural parameters.
$A(\lambda)$ is the log partition function, also known as the cumulant generating function and the free energy:
$$ A(\lambda) = \log \int \exp \langle \lambda, \phi(x) \rangle dx $$$A(\lambda)$ ensures that the distribution $p$ is normalized, i.e., $\int p_\lambda(x) dx = 1$. The space of natural parameters is given by the following:
$$ \Omega := \{ \lambda \in \mathbb{R}^d | A(\lambda) < +\infty \} $$i.e., $\lambda$ values that give us a finite $A(\lambda)$. The natural parameterization $\lambda$ of a Gaussian distribution has the following mapping to the standard parameterization $\theta$:
$$\lambda_1 = \frac{\mu}{\sigma^2}\\ \lambda_2 = -\frac{1}{2\sigma^2}$$It’s all about that A!
The key reason we use the expectation and natural parameterizations has to do with how they are related to each other, which happens through the log partition function $A(\lambda)$.
Indeed, when the exponential-family of distributions is represented with the minimal representation, which happens when the sufficient statistics $\phi_\alpha(x)$ are linearly independent, then there is a one-to-one mapping between the expectation parameters $\eta$ and the natural parameters $\lambda$. Note that a Gaussian distribution is fully specified by its first two moments.
We get the mapping between the parameterizations by applying the Legendre transformation to the log partition function $A(\lambda)$ to get its dual $A^*(\eta)$:
$$ \begin{aligned} A^*(\eta) &:= \max_\lambda \{ \langle \lambda, \eta \rangle - A(\lambda) \} \\ A(\lambda) &:= \max_\eta \{ \langle \lambda, \eta \rangle - A^*(\eta) \} \end{aligned} $$The above also give us the following gradients:
$$ \begin{aligned} \eta &= \nabla A(\lambda) \\ \lambda &= \nabla A^*(\eta) \end{aligned} $$Alright, so we can map between $\lambda$ and $\eta$. But why is this important? It’s because $A(\lambda)$ induces a Riemannian structure on the space of $\lambda$ and $\eta$. This stems from the fact that $A(\lambda)$ is a convex function, utilized to derive the Bergman divergence. This divergence is, in turn, equivalent to the Kullback-Leibler divergence for exponential-family distributions. There’s quite a bit happening in the previous sentence; for a more detailed derivations, refer to the first two chapters of Amari’s book “Information Geometry and Its Applications”. In the rest of this article, I will explain how the mapping between the Riemannian manifolds of $\lambda$ and $\eta$ gives us efficient natural gradients.
Riemannian Manifolds
A Riemannian manifold is a surface that could be warped such as the surface of a sphere, in contrast, a Euclidean manifold is flat (note that this is a handwavy definition). The following figure (from Amari 2016) illustrates a Riemannian manifold on the left and a Euclidean manifold on the right.
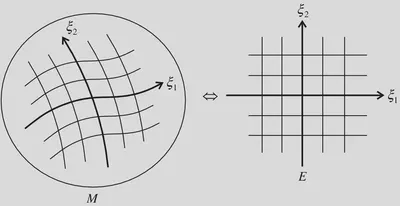
Since Riemannian manifolds are not always flat, the shortest path (known as the geodesic) between two point on the manifold is not always the euclidean distance. Instead, it is the euclidean distance scaled by $G$ called the Riemannian metric (or Riemannian metric tensor), which captures the curvature of the manifold at any given point $x$. For two points $x$ and $\hat{x}$, when $x-\hat{x}$ is small, the Euclidean and geodesic distances are given by the following:
$$ \begin{aligned} \text{Euclidean distance: } ||x-\hat{x}||^2_2 &= \sum^d_{i=1} (x_i - \hat{x}_i)^2 \\ \text{Geodesic distance: } ||x-\hat{x}||^2_G &= \sum^d_{i=1} \sum^d_{j=1} G_{ij}(x) dx_i d\hat{x}_j \end{aligned} $$Natural Gradients
Knowing that the natural parameters $\lambda$ and expectation parameters $\eta$ are in a Riemannian manifold has significant ramifications for gradient-based optimization methods, such as stochastic-gradient descent (SGD) which is formulated as follows for maximizing a function $\mathcal{L}$:
$$ \lambda_{t+1} = \lambda_{t} + \rho_t [\hat{\nabla}_\lambda \mathcal{L}(\lambda_t)] $$where $t$ is the iteration number, $\rho_t$ is the step size, and $\hat{\nabla}_\lambda \mathcal{L}(\lambda_t)$ is a stochastic estimate of the derivative of $\mathcal{L}$ at $\lambda_t$.
But this naive application of SGD ignores the Riemannian structure of the optimization variables when optimizing the parameters of an exponential-family distribution. This is clear from the following equivalent formulation of SGD:
$$ \lambda_{t+1} = \text{arg} \max_\lambda \lambda^\top[\hat{\nabla}_\lambda \mathcal{L}(\lambda_t)] - \frac{1}{2\rho}||\lambda-\lambda_t||^2_2 $$The above shows that SGD moves in the direction of the gradient while remaining close, in terms of the Euclidean distance, to the previous $\lambda_t$. However, since the natural parameters $\lambda$ are in a Riemannian manifold instead of a Euclidean manifold, the naive SGD formulation would be suboptimal.
Indeed, Amari 1998 proved that the steepest direction in Riemannian manifolds is not given by the ordinary gradients, instead it is given by the $\textit{natural gradients}$, which utilize the metric tensor $G$ of the Riemannian manifold to scale the gradients as follows:
$$ \tilde{\nabla}_\lambda \mathcal{L}(\lambda) = G^{-1}[\hat{\nabla}_\lambda \mathcal{L}(\lambda)] $$This gives us the following SGP updates with the natural gradients $\tilde{\nabla}_\lambda \mathcal{L}(\lambda)$:
$$ \begin{aligned} \lambda_{t+1} =& \lambda_{t} + \rho_t [\tilde{\nabla}_\lambda \mathcal{L}(\lambda_t)] \\ =& \lambda_{t} + \rho_t [G(\lambda_t)]^{-1}\hat{\nabla}_\lambda \mathcal{L}(\lambda_t) \end{aligned} $$The metric tensor $G$ is given by the Fisher Information Matrix, which can be computed for the natural parameterization as follows:
$$ G(\lambda) := \mathbb{E}_p[\nabla_\lambda \log p_\lambda (x) \nabla_\lambda \log p_\lambda (x)^\top] $$As such, by using the natural parameterization for the exponential-family distributions, we can leverage their Riemannian structure and compute their natural gradients, which results in faster convergence rate.
However, it is often computationally expensive to compute the metric tensor $G$ and invert it in most cases. This is where we further reap the benefits of using the natural parameterization for the exponential-family distributions. Khan and Nielsen 2018 proved that for an exponential-family in the minimal representation, the natural gradient with respect to the natural parameters $\lambda$ is equal to the gradient with respect to the expectation parameters $\eta$, and vice versa:
$$ \begin{aligned} \tilde{\nabla}_\lambda \mathcal{L}(\lambda) =& \nabla_\eta \mathcal{L}_*(\eta) \\ \tilde{\nabla}_\eta \mathcal{L}_*(\eta) =& \nabla_\lambda \mathcal{L}(\lambda) \end{aligned} $$Here $\mathcal{L}_*(\eta)$ is the optimization function with the expectation parameterization. This relation is a consequence of the mapping between the natural parameters $\lambda$ and the expectation parameters $\eta$ derived using the Legendre transformation.
The advantage of this is that if we use the natural parameterization $\lambda$, for conjugate models, the natural gradient $\tilde{\nabla}_\lambda \mathcal{L}(\lambda)$ does not require explicit computation of the Fisher Information Matrix. Note that the opposite is not true, i.e., the natural gradient of $\tilde{\nabla}_\eta \mathcal{L}_*(\eta)$ requires the explicit computation of the Fisher Information Matrix.
Indeed, the advantage of using using natural gradients with the natural parameterization $\lambda$ in conjugate models is clear in the context of variational inference:
$$ \tilde{\nabla}_\lambda \mathbb{E}_q \left[ \log \frac{p(x)}{q_\lambda(x)} \right] = [G(\lambda)]^{-1} \hat{\nabla}\mathbb{E}_q [\phi(x)^\top (\eta_0-\lambda) + A(\lambda)] = \eta_0 - \lambda $$As we can see, even though we used the natural gradients, the end result did not require use to explicitly compute the Fisher Information Matrix and invert it. Consequently, employing the natural parameterization for the Gaussian distribution, and more broadly for exponential-family distributions with conjugate models, yields faster convergence rates and computationally efficient natural gradient updates. Even in scenarios involving non-conjugate likelihoods, there are distinct advantages to utilizing natural parameters. For further insights into non-conjugate likelihoods, refer to the work by Khan and Lin 2017.
References
This article was based on what I learned from the following sources:
- Amari’s book—Information Geometry and Its Applications
- Amari’s paper on natural gradients
- Khan and Lin’s paper on Conjugate-computation Variational Inference (CVI)
- Khan and Nielsen’s paper on natural gradient descent
- Wainwright and Jordan’s book—Graphical Models, Exponential Families, and Variational Inference